Обзор вычислительной архитектуры Nvidia Ampere и графического процессора A100
Каждую весну компания Nvidia собирает GPU Technology Conference — большую конференцию с несколькими тысячами участников, посвященную аспектам применения графических процессоров в различных сферах. Основная часть конференции проходит в калифорнийском городе Сан-Хосе, и чаще всего именно на ней глава компании Дженсен Хуанг представляет новые архитектуры. Наш сайт по возможности старается не пропускать эти мероприятия, публикует новости с них и большие отчетные статьи. В новостях про Ampere и A100 мы уже вкратце рассказывали, настало время более подробного материала.
По понятным причинам мартовская конференция в этом году была отменена, и ее формат был переведен в цифровой. Конечно же, это довольно серьезно повлияло и на анонсы Nvidia. Сначала программное выступление главы было отменено вовсе, вроде как, но в мае он все-таки решил выступить перед сообществом, представив несколько новых продуктов, технологий и идей. Главными из которых являются новая архитектура Ampere и первый вычислительный процессор A100 на ее основе. Сегодня мы расскажем обо всех их особенностях подробно настолько, насколько это возможно на данный момент.
Вычислительные решения Nvidia уже много лет используются в весьма требовательных к производительности сферах, таких как глубокое обучение, анализ данных, научные вычисления, анализ видеоданных, облачные сервисы и многих других. Именно решения этой компании предоставляют необходимые возможности по ускорению большого количества вычислительных задач с параллельной обработкой огромных массивов данных, которыми заняты современные серверы.
Nvidia является одним из лидеров в деле освоения задач искусственного интеллекта, они предлагают вычислительные платформы, дающие многократный прирост в приложениях, использующих нейронные сети. Также их процессоры обеспечивают отличную скорость и в более традиционных высокопроизводительных вычислениях и при анализе больших объемов данных. Важно, что вычислительная платформа Nvidia универсальна, решения предлагаются в различных вариантах, от миниатюрных изделий для небольших роботов до мощнейших суперкомпьютеров.
В уже довольно далеком 2017 вышел ускоритель Tesla V100 с новым типом вычислительных блоков — тензорными ядрами, которые позволили в разы увеличить производительность матричных вычислений в задачах глубокого обучения, использующих мощь нейросетей. Через год вышла Tesla T4 на основе архитектуры Turing с тензорными ядрами и различными улучшениями эффективности. Тензорные ядра затем появились и в массовых решениях линейки GeForce на основе этой же архитектуры, и они позволили раскрыть некоторые возможности ИИ, вроде метода повышения производительности 3D-рендеринга под названием DLSS, который использует способности тензорных ядер.
Но сегодня мы говорим не об играх, а о куда более серьезных применениях GPU. Мощные вычислительные решения компании показали отличные результаты в индустриальных тестах производительности и были хорошо приняты рынком, да и пользовательские продукты и решения для автопилотируемых автомобилей и роботов также завоевали определенный успех. Немалая его доля была достигнута и за счет программного обеспечения — весьма удачной платформы для разработки CUDA, включающей API, библиотеки, программные стеки и оптимизаторы — все это и помогло раскрыть возможности аппаратных решений Nvidia, которые выпускаются несколько лет подряд. Этой весной пришло время обновить архитектуру и выпустить новый ускоритель вычислений — A100.
Графический процессор Nvidia A100 Tensor Core
Для начала, давайте сразу разберемся с названиями, а то многих слегка запутали схожие названия, относящиеся к несколько разным вещам. GA100 — это внутреннее кодовое имя чипа, а A100 — наименование первого решения компании на основе этого чипа (аналогично GV100 и V100 для Volta). Это важно в том числе и потому, что технические характеристики полного чипа и решений на его основе могут отличаться. В частности, у A100 некоторые из исполнительных блоков неактивны, о чем мы подробно расскажем далее. А ведь есть еще и DGX A100 — уже готовая система Nvidia на базе одноименного процессора. Вот такая путаница.
Итак, вычислительный процессор «A100 Tensor Core» (полное название показывает важность тензорных ядер, но мы его сократим до A100) основан на новой архитектуре Ampere, и, по сравнению с аналогом из предыдущего поколения в виде Tesla V100, добавляет немало новых возможностей и обеспечивает более высокую производительность в различных типах вычислительных задач — ИИ, при анализе данных, в высокопроизводительных вычислениях и многих других задачах.
Также A100 обеспечивает гибкое масштабирование для вычислительных задач в составе рабочих станций с одним или несколькими GPU, в серверах, кластерах, облачных центрах обработки данных, суперкомпьютерах и т. д. Новый графический процессор позволяет создавать масштабируемые и универсальные высокопроизводительные центры обработки данных с разным количеством GPU, от одного до сотен штук.

Новый SXM4-модуль с A100
Чип GA100 производится на тайваньской фабрике TSMC по новому для компании Nvidia техпроцессу N7 — они впервые используют 7 нм для производства своих GPU. Да и вообще, такой большой и сравнительно массовый чип на основе этого техпроцесса компания TSMC выпускает впервые — GA100 включает 54,2 млрд транзисторов и имеет площадь кристалла в 826 мм² (физические размеры чипа составляют порядка 26×32 мм). По словам главы компании Nvidia, они выжали максимум возможного из этого техпроцесса, и в это довольно легко поверить, глядя на характеристики нового GPU.
Кратко перечислим главные особенности A100. Во-первых, в нем применяется уже третье поколение тензорных ядер, которые были серьезно модифицированы, по сравнению с аналогичными исполнительными устройствами V100. Они стали более гибкими и производительными, а также получили некоторые нововведения, предназначенные для упрощения их использования разработчиками. Одним из самых важных изменений стал новый формат вычислений TensorFloat-32 (TF32) для задач ИИ, который способен повысить скорость таких вычислений до 10-20 раз для формата FP32 в уже существующих задачах — при этом, изменения кода не требуется.
Также тензорные ядра A100 поддерживают и формат вычислений FP64 (IEEE-совместимый), что повышает скорость работы в высокопроизводительных вычислениях до 2,5 раз по сравнению с Volta. Такой же прирост скорости новинка обеспечивает и для операций смешанной точности FP16/FP32 по сравнению с V100 — для этого пригодится еще один новый тип операций — Bfloat16 (BF16), который обсчитывается на той же скорости, что и операции со смешанной точностью FP16/FP32. Что касается ускорения INT8, INT4 и бинарных операций при инференсе в задачах глубокого обучения, то преимущество A100 в них может достигать 10-20 раз, а то и больше.
Для наглядности приведем таблицу возможностей A100 и V100 по вычислениям в основных форматах и на различных исполнительных блоках, которые используются в высокопроизводительных вычислениях и задачах ИИ (уточнение TC означает использование возможностей тензорных ядер). Все значения даны с учетом турбо-частоты GPU (1410 МГц), а значения в скобках — эффективная производительность с учетом разреженности данных, о которой написано далее.
| Пиковая производительность | V100 | A100 | Ускорение |
|---|---|---|---|
| A100 FP16 против V100 FP16 | 31,4 тфлопс | 78 тфлопс | 2,5× |
| A100 FP16 TC против V100 FP16 TC | 125 тфлопс | 312 (624) тфлопс | 2,5× (5×) |
| A100 BF16 TC против V100 FP16 TC | 125 тфлопс | 312 (624) тфлопс | 2,5× (5×) |
| A100 FP32 против V100 FP32 | 15,7 тфлопс | 19,5 тфлопс | 1,25× |
| A100 TF32 TC против V100 FP32 | 15,7 тфлопс | 156 (312) тфлопс | 10× (20×) |
| A100 FP64 против V100 FP64 | 7,8 тфлопс | 9,7 тфлопс | 1,25× |
| A100 FP64 TC против V100 FP64 | 7,8 тфлопс | 19,5 тфлопс | 2,5× |
| A100 INT8 TC против V100 INT8 | 62 TOPS | 624 (1248) TOPS | 10× (20×) |
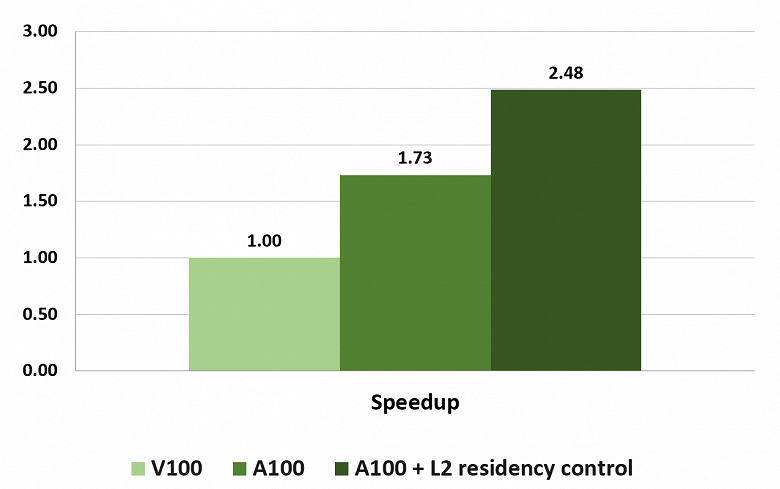
Но это лишь пиковые теоретические цифры, вряд ли достижимые на практике. Давайте посмотрим на то, что получается в конкретных задачах. По данным самой компании Nvidia, графический процессор A100 обеспечивает увеличение производительности над V100 в реальных задачах по тренировке и инференсу ИИ, и преимущество новинки в них достигает нескольких раз.
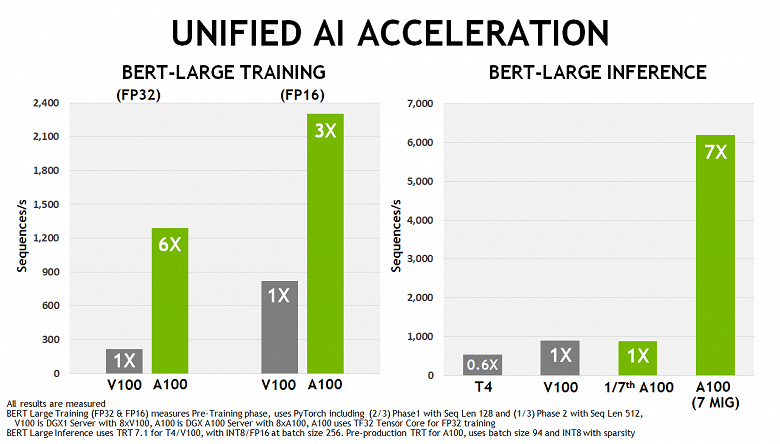
На диаграмме сравнивается скорость аналогичных 8-процессорных решений на основе вычислительных процессоров A100 и V100 в сценариях глубокого обучения BERT. При обучении нейросети, преимущество A100 составляет от 3 раз для FP16-точности до 6 раз для FP32 (на A100 автоматически используется формат TF32), а при инференсе A100 уже в 7 раз быстрее, так как позволяет запускать на одном чипе сразу семь виртуальных GPU, каждый со скоростью одного V100, чего вполне достаточно для этой нагрузки.
Понятно, что такие условия специально подобраны для того, чтобы показать новые возможности A100, да еще и используются несколько разные форматы вычислений, но и преимущество получилось очень большим. А что мы увидим в задачах высокопроизводительных вычислений, в которых новый GPU даже по теории должен быть мощнее лишь в пару-тройку раз от силы?
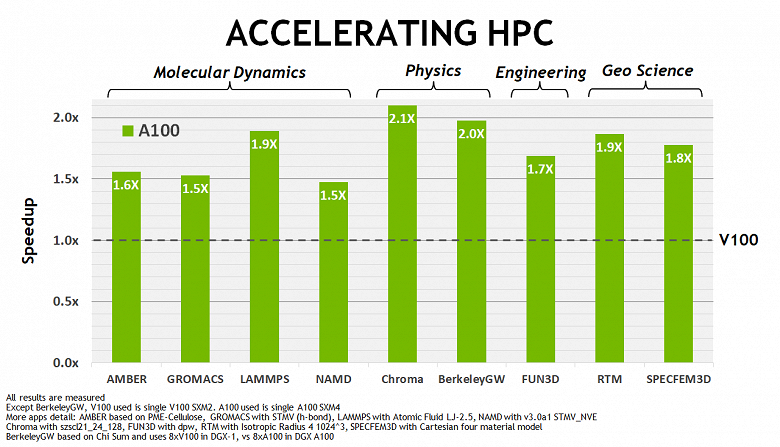
Судя по данным Nvidia, сразу в нескольких подобных задачах новый A100 показывает приличное ускорение, по сравнению с Tesla V100 — преимущество новинки в основном составляет 1,5-2 раза. Конечно, это заметно меньше, чем 6-7 раз в сфере ИИ, но ведь упор в случае Ampere делался в основном на тензорные операции. А для HPC-задач ускорение вдвое при даже меньшей теоретической разнице в пиковом темпе FP64-вычислений (если не брать возможности тензорных ядер), выглядит неплохо. Наверняка также сказываются и многочисленные оптимизации подсистемы памяти и кэширования. Обо всем этом мы сейчас и поговорим подробнее.
Архитектурные новшества Ampere
Все современные графические процессоры Nvidia состоят из укрупненных блоков — потоковых мультипроцессоров (streaming multiprocessor — SM), и архитектура Ampere и чип GA100 — не исключение. Как и более ранние графические процессоры компании Nvidia, новый чип состоит из нескольких кластеров GPU processing cluster (GPC), которые содержат кластеры текстурной обработки (TPC — texture processing cluster), а те, в свою очередь, составлены уже из потоковых мультипроцессоров (SM — streaming multiprocessor). Также в состав чипа входят контроллеры памяти (в случае GA100 — HBM2-памяти), кэш-память второго уровня и управляющая логика.
Полная модификация чипа GA100 включает 8 GPC из 8 TPC каждый, по два SM на каждый TPC — то есть 128 мультипроцессоров всего. Каждый мультипроцессор состоит из 64 CUDA-ядер для FP32-вычислений, и общее их количество на чип составляет 8192 штуки. Каждый мультипроцессор также имеет по четыре тензорных ядра, что дает в результате 512 тензорных ядер на GPU. Что касается видеопамяти, то на чипе может быть установлено до 6 стеков HBM2-памяти, которую обслуживают 12 контроллеров с шириной шины по 512 бит каждый.
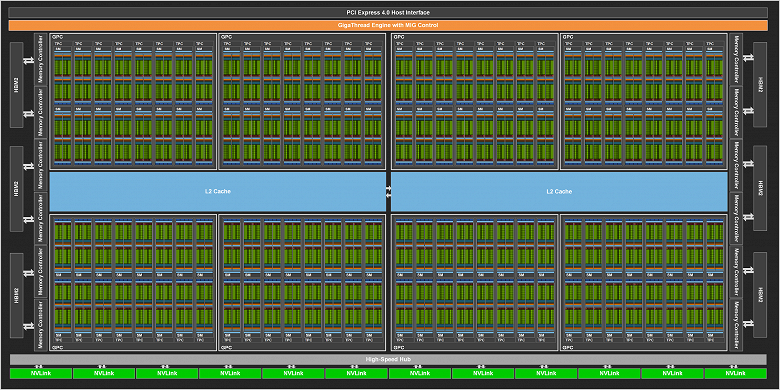
Схема полной версии чипа GA100
А теперь внимание: в отличие от полной версии GA100, в конкретной модели A100, которая была анонсирована недавно, было отключено несколько исполнительных блоков. В частности, неактивен один из кластеров GPC, также может быть 7 или 8 разблокированных текстурных кластера на каждый GPC. То есть в целом эта версия чипа содержит лишь 108 мультипроцессоров SM с общим количество CUDA-ядер в 6912 штуки и 432 тензорными ядрами. Память тоже немного порезали — до пяти стеков HBM2-памяти и десятка 512-битных контроллеров.
Изменения в мультипроцессорах
Новый мультипроцессор архитектуры Ampere хоть и основан на том, что мы уже видели в Volta и Turing, но в него добавлены несколько новых возможностей. Так, мультипроцессоры прошлых двух поколений имеют по восемь тензорных ядер на SM, и каждое из них умеет исполнять 64 FMA-операции смешанной точности (FP16/FP32) за такт. А мультипроцессоры в GA100 имеют улучшенные тензорные ядра третьего поколения, которые исполняют по 256 FMA-операций FP16/FP32 за такт, поэтому вполне достаточно и четырех таких ядер на каждый SM, ведь общие вычислительные возможности GA100 даже в таком случае выросли вдвое по сравнению с Volta и Turing — с 512 до 1024 операций с точностью FP16/FP32 за такт.
Ключевые возможности мультипроцессоров Ampere:
- Тензорные ядра третьего поколения
- Ускорение всех типов данных, включая форматы FP16, BF16, TF32, FP64, INT8, INT4 и бинарного
- Новая возможность, использующая разреженность нейросетей, удваивающая производительность стандартных тензорных операций
- TF32-операции, обеспечивающие простой метод ускорения вычислений над данными формата FP32 в нейросетях и высокопроизводительных вычислениях, исполняющиеся в 10 раз быстрее, чем FP32 FMA-операции на V100, и в 20 раз быстрее, если используется разреженность матриц
- Операции со смешанной точностью FP16/FP32 для глубокого обучения, работающие в 2,5 раза быстрее, чем на V100 (и в 5 раз быстрее при использовании разреженности)
- Операции со смешанной точностью BF16/FP32, работающие с той же производительностью, что и FP16/FP32-операции
- Тензорные FP64-операции двойной точности, предназначенные для высокопроизводительных вычислений и выполняющиеся в 2,5 раза быстрее, чем FP64 DFMA-операции на V100
- INT8-операции с использованием разреженности с высочайшей производительностью, используемые для задач референса при глубоком обучении, работающие в 20 раз быстрее, чем аналогичные операции на V100
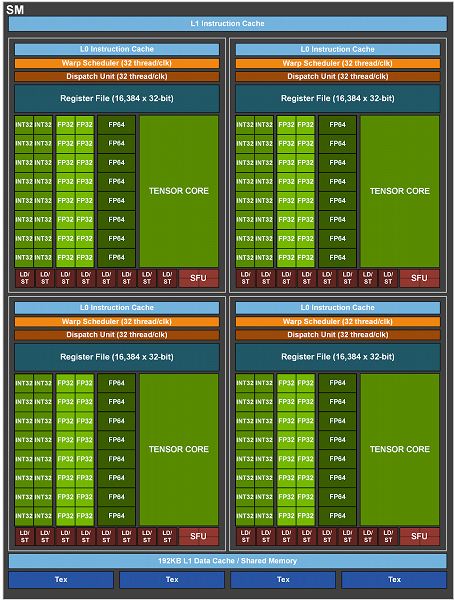
Потоковый мультипроцессор GA100
Кроме разного количества блоков и описанной выше разницы в объеме L1-кэша и общей памяти, на схеме мультипроцессора все выглядит довольно знакомо. Единственное, что наметанный взгляд постоянного читателя нашего раздела может заметить, так это то, что на диаграмме нет RT-ядер, которые были в Turing. Все верно, аппаратной поддержки трассировки в GA100 нет. Но это неудивительно, ведь эта модель GPU — чисто вычислительный процессор, которому RT-ядра просто не нужны. Как и блок кодирования видеоданных NVEnc, например, и разъемы вывода информации на дисплеи. Все это обязательно появится далее в игровых решениях семейства GeForce и профессиональных графических видеокартах Quadro.
На следующей схеме показана разница в темпе исполнения стандартных операций над данными различных типов на процессорах V100 и A100: FP16, FP32 против TF32, FP64 и INT8, соответственно. Естественно, больше всего выросла производительность в тех случаях, когда вместо основных исполнительных блоков V100 вычисления проводятся при помощи тензорных блоков A100, которые получили расширенную поддержку разных форматов, да еще и с учетом возможности использования разреженности матриц на A100.
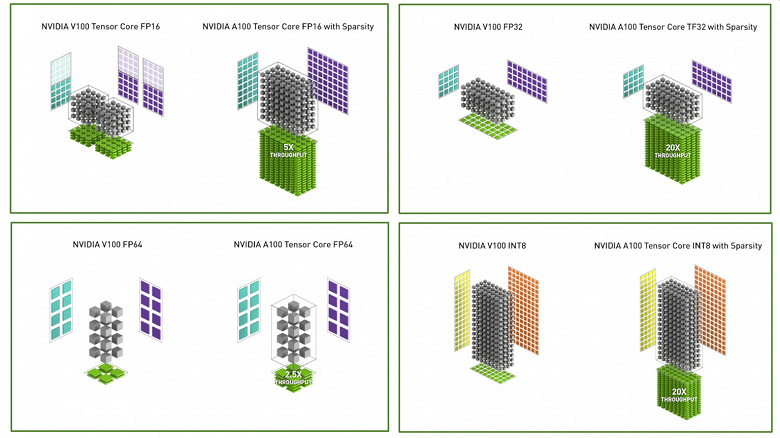
В случае с FP16-форматом у V100 показано два столбца тензорных ядер, так как каждый мультипроцессор этого GPU содержит по два тензорных ядра, а у A100 он всего один. Но все равно, с учетом разреженности, прирост скорости на Ampere достигает 5 раз в пике, а без разреженности — 2,5 раза, что тоже совсем неплохо.
Рассмотрим новый формат вычислений TensorFloat-32 (TF32) — он обеспечивает ускорение операций над данными в FP32-формате в задачах глубокого обучения хитрым образом. Для удобства числа с плавающей запятой представляются в экспоненциальной записи — к примеру, для формата FP32 один бит отводится на знак числа, 8 бит уходит на порядок (экспоненту), который определяет максимально возможный диапазон чисел, а оставшиеся 23 бита — на мантиссу, обеспечивающую точность вычислений.
Для FP16-формата меньше и порядок (лишь 5 бит) и точность (10 бит). Такие вычисления в современных GPU производятся значительно быстрее, но зачастую разработчикам в задачах глубокого обучения хватает и той точности, которая обеспечивается 10-битной мантиссой, но бывает недостаточно диапазона значений, который могут дать 5 бит в FP16-формате.
Поэтому сейчас большинство задач ИИ для обучения используют формат FP32, который не ускоряется на тензорных ядрах, и Nvidia вышла из положения хитрым образом, представив новый 32-битный формат вычислений TF32, обеспечивающий диапазон значений FP32 при точности FP16: 8-битная экспонента и 10-битная мантисса. Но самое главное — такие вычисления проводятся над FP32-значениями на входе, да и на выход подается именно FP32, и накопление данных при этом производится в формате FP32, так что точность не теряется.
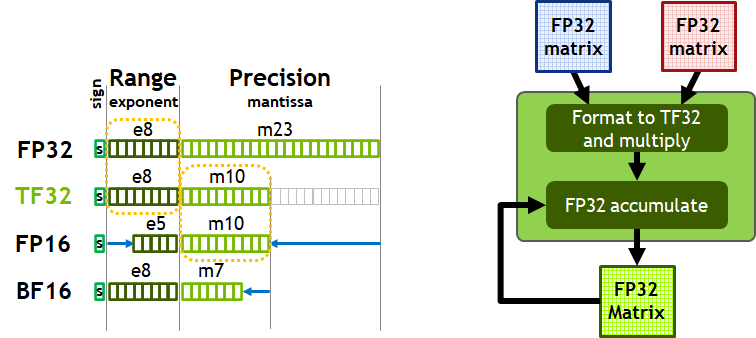
Архитектура Ampere использует TF32-вычисления при использовании тензорных ядер над данными формата FP32 по умолчанию, пользователю не нужно ничего делать для этого, он получит ускорение автоматически. А вот не тензорные операции будут использовать обычные FP32-блоки. Но на выходе в обоих случаях — стандартный IEEE FP32-формат. Автоматическое использование смешанной точности BF16 позволяет еще вдвое повысить производительность, по сравнению с TF32, но для этого понадобится поменять пару строк кода.
То есть для процесса обучения нейросетей у разработчика при использовании A100 есть два высокопроизводительных варианта:
- (По умолчанию) Используются тензорные ядра TF32, ничего изменять в пользовательских скриптах для этого не нужно. Такой подход позволяет получить восьмикратное ускорение по отношению к FP32 на GA100 и до 10-кратного преимущества над GV100.
- Для максимальной скорости тренировки нейросетей нужно использовать FP16 или формат со смешанной точностью BF16, который дает двойное ускорение по сравнению с TF32, и до 16-кратного по сравнению с FP32. Если же сравнивать с Volta, то новый GA100 будет до 20 раз быстрее в таких условиях.

Мы говорили о теоретических пиковых показателях, но на диаграмме выше можно оценить примерную производительность тензорных вычислений при перемножении матриц разных размеров по данным компании Nvidia. Как видите, использование новых типов тензорных операций над матрицами на A100 позволяет увеличить производительность вычислений в несколько раз. И это уже не теоретическая, а практическая производительность.
Ускорение высокопроизводительных вычислений на тензорных ядрах
Кроме задач искусственного интеллекта, не менее важными являются высокопроизводительные вычисления (HPC), и потребность в высокой скорости в таких системах растет огромными темпами. Такие вычисления используются большим количеством научных приложений, которые предпочитают формат двойной точности FP64 — именно по причине его высокой точности, простите за тавтологию.
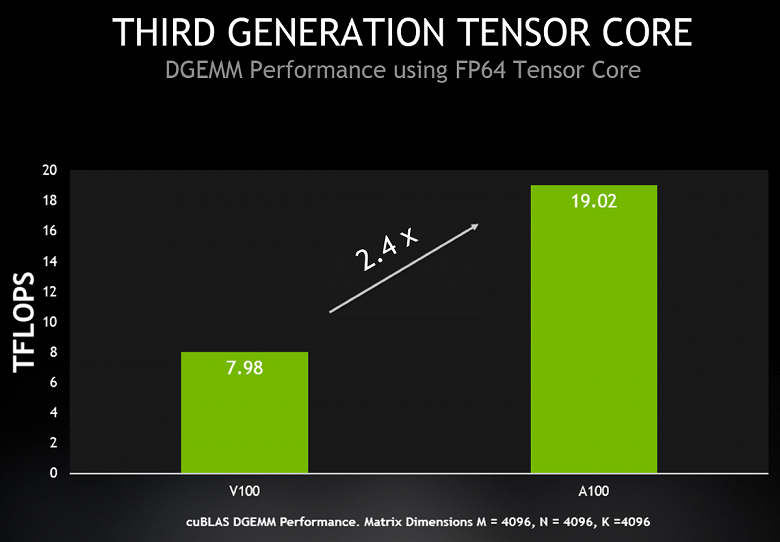
Для того, чтобы улучшить характеристики A100 в этом плане, в Nvidia решили обеспечить новый графический процессор A100 возможностью исполнения таких операций и на тензорных ядрах, а не только основных. И A100 теперь поддерживает ускорение вычисления в IEEE-совместимом формате FP64 на тензорных ядрах, обеспечивая пиковую производительность в 2,5 раза выше, чему Tesla V100. Новая инструкция для совмещенного умножения-сложения матриц с двойной точностью у A100 заменяет сразу восемь DFMA-инструкций на V100, что сокращает количество выборок команд и чтение из регистров, снижает накладные расходы и требования к пропускной способности разделяемой памяти.
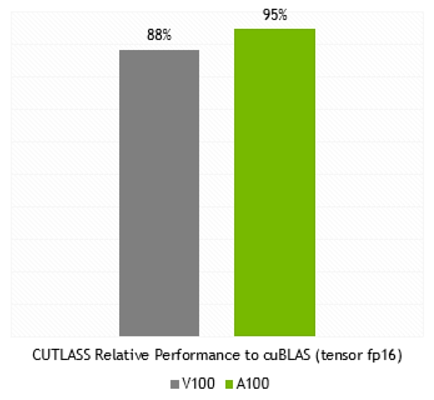
Каждый мультипроцессор SM умеет вычислять 64 такие FMA-операции с точностью FP64 за один такт (то есть всего 128 FP64-операций за такт), что вдвое больше, чем у Tesla V100. И 108 активных мультипроцессоров в составе A100 обеспечивают пиковую производительность для FP64 в 19,5 терафлопс, что в 2,5 раза больше, чем может V100. Причем, почти такой же прирост уже можно получить и в реальности — в cuBLAS DGEMM, умеющем использовать новые возможности A100.
Приведем сводную сравнительную таблицу характеристик процессоров A100, V100 и P100, а также сравнение их пиковой теоретической производительности для разных типов данных и операций. В следующей таблице показаны отличия между GPU производства Nvidia трех разных поколений, с учетом их турбо-частот. В скобках указаны данные пиковой производительности A100 с учетом разреженности матриц, о которой написано в следующем разделе нашего материала.
Модель GPU P100 V100 A100 Кодовое имя GP100 GV100 GA100 Архитектура Pascal Volta Ampere Техпроцесс, нм 16 12 7 Кол-во транзисторов, млрд 15,3 21,1 54,2 Площадь кристалла, мм² 610 815 826 Потребление энергии, Вт 300 300 400 Кол-во мультипроцессоров 56 80 108 Кол-во кластеров TPC 28 40 54 Кол-во FP32-ядер 3584 5120 6912 Кол-во FP64-ядер 1792 2560 3456 Кол-во INT32-ядер — 5120 6912 Кол-во тензорных ядер — 640 432 Турбо-частота, МГц 1480 1530 1410 Производительность тензорных FP16, терафлопс — 125 312 (624) Производительность тензорных BF16, терафлопс — — 312 (624) Производительность тензорных TF16, терафлопс — — 156 (312) Производительность тензорных FP64, терафлопс — — 19,5 Производительность тензорных INT8, топс — — 624 (1248) Производительность тензорных INT4, топс — — 1248 (2496) Производительность FP16, терафлопс 21,2 31,4 78 Производительность BF16, терафлопс — — 39 Производительность FP32, терафлопс 10,6 15,7 19,5 Производительность FP64, терафлопс 5,3 7,8 9,7 Производительность INT32, топс — 15,7 19,5 Кол-во текстурных модулей 224 320 432 Ширина HBM2-памяти, бит 4096 4096 5120 Объем памяти, ГБ 16 16/32 40 Частота памяти, МГц 703 877,5 1215 Пропускная способность памяти, ГБ/с 720 900 1555 Объем L2-кэша, МБ 4 6 40 Объем разделяемой памяти на SM, КБ 64 До 96 До 164 Объем регистрового файла, КБ 14336 20480 27648 Хорошо видно, что с каждым поколением Nvidia не только тупо ускоряла математическую производительность исполнительных блоков GPU и увеличивала кэши, но и внедряла все более широкие возможности по исполнению специфических вычислений с повышенной производительностью, а также улучшала общую эффективность своих процессоров. В особенности это касается различных типов вычислений на тензорных блоках, но не только их. Увы, и без минусов не обошлось — потребление энергии новым GPU выросло с 300 до 400 Вт, и это — при отключенной части чипа. Похоже, что высокое потребление энергии является одним из его недостатков.
Использование разреженных матриц
В A100 также внедрили новую технологию структурированной разреженности (Structured Sparsity), которая помогает удвоить производительность вычислений над матрицами, используя разреженность данных. Разреженная матрица — это матрица с преимущественно нулевыми элементами в ней, и подобные матрицы довольно часто встречаются в приложениях, связанных с использованием ИИ.
Так как нейросети способны адаптировать весовые коэффициенты в процессе обучения на основе его результатов, то подобное структурное ограничение не особенно влияет на точность обученной сети для инференса, что позволяет выполнять его с разреженностью. Чтобы получить повышение производительности, нужно использовать разреженность на ранних этапах обучения, и подобное ускорение без потерь в точности является предметом для дальнейших исследований.
Структура использует определение разреженной матрицы в виде 2:4, которая допускает два ненулевых значения в каждом векторе с четырьмя входными значениями. A100 поддерживает структурированную разреженность 2:4 построчно, как показано на схеме. Благодаря четкой структуре матрицы, ее можно эффективно сжать, сократив требуемый объем памяти и пропускную способность почти вдвое.
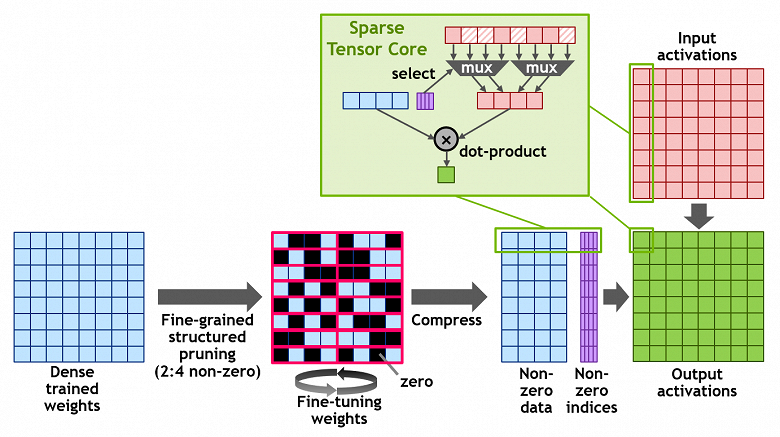
В Nvidia разработали универсальный метод прореживания нейросетей для инференса, используя структурированный шаблон разреженности 2:4. Сначала сеть обучается с использованием плотных весов, затем применяется мелкозернистое структурированное прореживание, а оставшиеся ненулевые веса корректируются на дополнительных этапах обучения. Такой метод вроде бы не приводит к значительной потере точности инференса на примере десятков проверенных специалистами компании нейросетей, включая задачи машинного зрения, определения объектов, сегментацию, перевод с одного языка на другой и т. д.
Чтобы все это работало, графический процессор A100 поддерживает новые инструкции Sparse Tensor Core, пропускающие вычисления для записей с нулевыми значениями, что и приводит к удвоению производительности вычислений, использующих разреженность матриц.
Одновременное исполнение операций FP32 и INT32
Как и все решения семейств Volta и Turing, новый GPU архитектуры Ampere A100 содержит отдельные вычислительные ядра FP32 и INT32, что позволяет одновременно исполнять соответствующие виды операций каждый такт, что увеличивает скорость выдачи команд. Мы уже неоднократно останавливались на этой возможности, которая помогает повысить производительность в некоторых задачах. Многие приложения содержат циклы, выполняющие вычисления целочисленных адресов памяти в сочетании с вычислениями с плавающей запятой, вот они и получат преимущество от одновременного исполнения операций FP32 и INT32.
Подсистема памяти и кэширования
Повышение производительности мультипроцессоров не имеет смысла без соответствующей поддержки со стороны подсистемы памяти и ее кэширования. Если просто повысить возможности исполнительных блоков, то «прокормить» их данными без увеличения пропускной способности и снижения задержек просто не получится, и роста производительности не произойдет.
Кэш-память первого уровня, объединенная с разделяемой памятью, была впервые представлена в Tesla V100, и это архитектурное решение значительно повысило производительность во многих задачах, а также упростило программирование, снизив необходимость в кропотливой оптимизации для того, чтобы добиться близкой к пиковой производительности. В A100 в полтора раза увеличили объем объединенного блока L1-кэша и общей памяти, по сравнению с их объемом в V100 — 192 КБ против 128 КБ на каждый мультипроцессор. Во многих задачах высокопроизводительных вычислений и ИИ одно это изменение дает приличный прирост производительности.
Так как требовательность высокопроизводительных вычислений, аналитики и задач ИИ к пропускной способности памяти и ее объему постоянно растут, то в Tesla P100 впервые внедрили HBM2-память, работающую с очень высокой пропускной способностью, а в Tesla V100 улучшили ее реализацию. Напомним, что тип памяти HBM2 отличается тем, что стеки чипов памяти расположены прямо на той же упаковке вместе с кристаллом графического процессора, что как раз и обеспечивает рост пропускной способности, а также снижение потребления и требуемой площади, по сравнению с традиционными типами памяти вроде GDDR5/GDDR6. Кроме роста ПСП, это решение также позволяет установить в серверы большее количество GPU.
Неудивительно, что и продукт на архитектуре Ampere получил определенные улучшения в этом плане. Новый графический процессор GA100 несет на себе 48 ГБ оперативной памяти типа HBM2 в виде шести стеков по 8 кристаллов, которые присоединены к GPU при помощи 12 контроллеров памяти с общей шириной шины в 6144-бит. Но конкретно модификация A100 слегка урезана и по возможностям памяти — в ней отключена пара контроллеров памяти и один стек HBM2, поэтому активными остались лишь пять стеков. Соответственно, общий объем памяти в новом решении сократился до 40 ГБ, а ширина шины до 5120 бит. И так как память в A100 работает на частоте 1215 МГц (DDR), то это обеспечивает пропускную способность памяти в 1,555 ТБ/с, что более чем в 1,7 раза выше пропускной способности памяти у V100.

Уточним, что мы говорим о конкретном решении A100, а у полного чипа GA100 видеопамяти установлено 48 ГБ — как понятно по фотографии чипа, они составлены шестью стеками. В случае A100 один из них отключен вместе с соответствующими контроллерами памяти. Интересно, что не участвующий в работе стек памяти полностью работоспособен, он просто отключен. Возможно, не ставить его на упаковку вовсе получается чуть ли не затратнее, чем просто отсоединить.
Вполне возможно, что со временем компания Nvidia выпустит и более мощное решение на основе полноценного GA100. Вероятнее всего, сейчас они упираются в высокое энергопотребление и тепловыделение A100, достигающее 400 Вт. К слову, количество памяти в 40 ГБ и не слишком сильно смотрится на фоне 32 ГБ у последней модификации V100, ведь все остальные характеристики чипа увеличили в два и более раз.
Подсистема памяти A100 HBM2 поддерживает исправление ошибок ECC с исправлением одиночной ошибки (single-error correcting double-error detection — SECDED) для защиты данных. ECC обеспечивает более высокую надежность для вычислений, чувствительных к повреждению данных, что важно в масштабных многокластерных вычислительных средах, в которых GPU обрабатывают большие объемы данных на протяжении длительного времени. В A100 также защищены SECDED ECC и другие структуры памяти — кэш-память первого и второго уровней, а также регистровые файлы в мультипроцессорах.
Еще более важными являются изменения в кэш-памяти второго уровня, которые можно назвать чуть ли не революционными! Графический процессор GA100 содержит 48 МБ кэш-памяти второго уровня, а модификация A100 лишена его 1/6 части, поэтому активным объемом является 40 МБ, что в 6,7 раз больше, чем у V100 — и это очень большой прирост! Такой объем кэша позволит заметно реже лазить в разы более медленную видеопамять, и это увеличит производительность во многих вычислительных задачах.
Инженеры Nvidia пришли к такому объему опытным путем — проверяя, что дают разные объемы кэша в имитации различных типов вычислений. Ну и новый техпроцесс позволил им добавить много L2-кэша, оставаясь в рамках определенного размера кристалла, конечно же. Возможно, эти лишние транзисторы также пригодились и для того, чтобы сделать кристалл физически большего размера — для более эффективного отвода тепла от него.
Но мы отвлеклись, а ведь интересное в этом разделе только начинается. Если вы обратите внимание на диаграмму чипа или фото его ядра, то заметите новую структуру разделенного кэша с кроссбаром. L2-кэш в GA100 разделен на два раздела — для того, чтобы обеспечить более широкую полосу пропускания и снизить задержки доступа к памяти для каждой половины мультипроцессоров. Каждый из двух разделов L2-кэша локализует и кэширует данные для доступа к памяти от мультипроцессоров в тех кластерах GPC, которые напрямую подключены именно к этому разделу.
Такая структура позволила увеличить пропускную способность L2-кэша в 2,3 раза по сравнению с V100. Специалистам Nvidia пришлось так сделать, так как аналогичное V100 решение кэширования второго уровня попросту было бы неспособно прокормить данными увеличенное количество более мощных мультипроцессоров конфигурации Ampere, ведь их требования превышают возможности L2-кэша Volta в 1,3-2,5 раза, как видно по прикидкам:

На схеме показано, что гипотетический V100 с улучшенными до уровня A100 тензорными ядрами не смог бы получить достаточное количество данных из кэш-памяти. Правда, с разделенным L2 в редких случаях задержки могут и увеличиться, если какому-то мультипроцессору вдруг понадобятся данные из другого раздела. Но это лишь в теории. Когерентность кэша на аппаратном уровне поддерживается моделью программирования CUDA, и приложения автоматически будут использовать преимущества новой организации L2-кэша.
Существенное увеличение объема L2-кэша в GA100 значительно повышает производительность многих алгоритмов высокопроизводительных вычислений и задач ИИ, так как это позволяет кэшировать большие части наборов данных и моделей, получая доступ к ним с гораздо большей скоростью и меньшими задержками, по сравнению с чтением и записью в память HBM2. Некоторые рабочие нагрузки, ограниченные именно ПСП, вроде нейросетей с небольшим размером пакетов, больше других выиграют от увеличенного объема L2-кэша, и разница в скорости будет многократной.
А чтобы оптимизировать использование столь немалого объема кэш-памяти, в архитектуре Ampere появилась возможность управления процессом кэширования данных в L2-кэше. A100 предоставляет новые элементы управления L2-кэшем для указания данных, которые нужно хранить в кэш-памяти. Так, в A100 можно прямо выделить часть L2-кэша (максимум до 30 МБ) для постоянного сохранения некоторых данных.

Например, для задач глубокого обучения, пинг-понг буферы можно постоянно закэшировать в L2-кэше для максимально быстрого доступа к этим данным, как и для предотвращения их обратной записи в HBM2-память. И для реализации модели «поставщик-потребитель» при обучении нейросетей, при помощи управления L2-кэшем также можно оптимизировать процесс кэширования, как и во многих других задачах. Увеличение производительности в некоторых из применений добавляет к уже и так неплохим результатам A100 по сравнению с V100, еще и дополнительный весомый прирост.
Но и это еще не все изменения в подсистеме памяти архитектуры Ampere. Также была добавлена возможность сжатия данных, находящихся в L2-кэше и локальной памяти GPU. Nvidia не делится конкретным алгоритмом, но это довольно простой метод сжатия без потерь, когда сжимаются данные с нулями или одинаковыми значениями. Берутся две соседние строки L1-кэша — 8 блоков по 32 байта, в них ищутся одинаковые байты. Если таких байтов достаточно много, то один или несколько из 32-байтных блоков в L2/глобальную память не попадает.

Сжатие данных обеспечивает увеличение пропускной способности чтения и записи HBM2-памяти и чтения из L2-кэша до четырех раз (запись в L2 ускоряется вдвое), и до двукратного увеличения эффективного объема L2. Причем, подобного ускорения можно добиться и во вполне реальных примерах — например, в задаче линейной алгебры SAXPY (Scalar Alpha X Plus Y) — скалярном умножении и векторном сложении с разным количеством блоков:
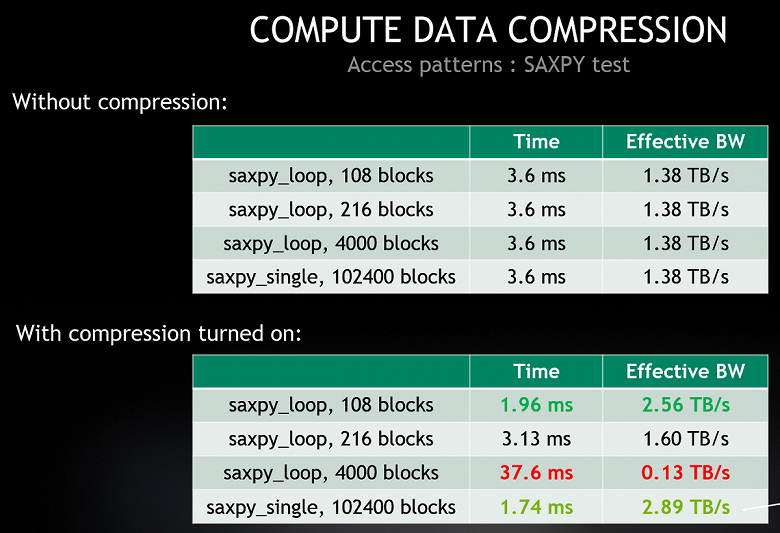
Как видите по таблице, сжатие данных не всегда приводит к положительному результату, возможен и обратный пример, когда оно не просто бесполезно, но даже вредит. Зато когда работает эффективно, то прирост скорости приличный. Автоматически режим компрессии не включается, надо выделять память специальной командой. Эффективная пропускная способность даже в реальной задаче может быть повышена вдвое, но полезность сжатия данных в кэше нужно проверять в каждом конкретном случае.
Асинхронное копирование и асинхронные барьеры
Графический процессор A100 включает новую инструкцию асинхронного копирования, которая загружает данные напрямую из памяти GPU (через L2-кэш) в разделяемую память мультипроцессора SM, минуя регистровый файл и даже L1-кэш, при необходимости. Асинхронное копирование уменьшает нагрузку на регистровый файл, используя меньше регистров, эффективнее использует пропускную способность памяти, давая другим данным возможность дольше сохраняться в L1, и все это в итоге увеличивает эффективность вычислений, снижая энергопотребление.
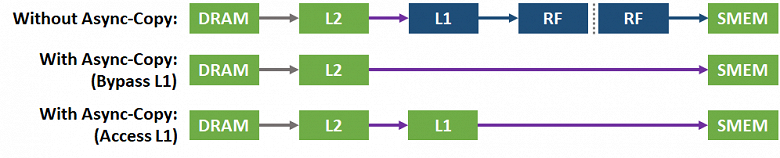
Асинхронное копирование может выполняться в фоновом режиме — в то время, когда мультипроцессор выполняет другие вычисления. И результаты в некоторых примерах поражают — мало того, что оптимизация загрузки и хранения данных в разделяемой памяти A100 и так значительно выше, чем у V100, асинхронное копирование дает еще больший прирост, и в итоге разница достигает 3-4 раз и даже более:
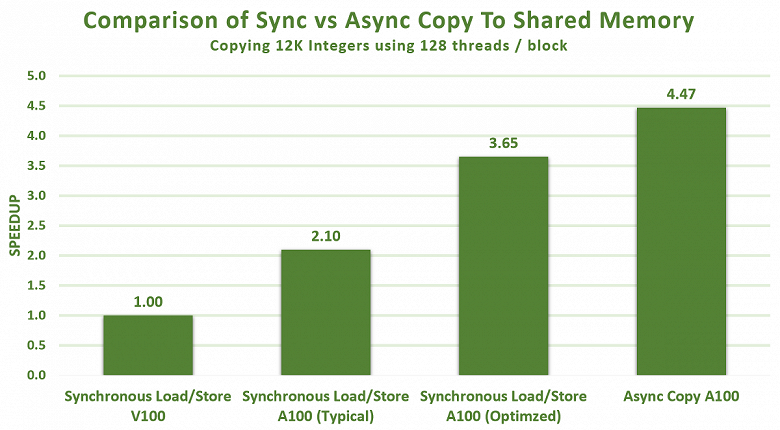
Также A100 поддерживает аппаратно-ускоренные асинхронные барьеры в разделяемой памяти. Их использование доступно в CUDA 11 в форме объектов барьеров ISO C++. Асинхронные барьеры могут использоваться для перекрытия асинхронных копий из глобальной памяти в общую с вычислениями в мультипроцессоре, их можно использовать для реализации модели «поставщик-потребитель». Барьеры также дают механизмы для синхронизации потоков CUDA на разных уровнях детализации, а не только на уровне варпа или блока.
Нововведения в передаче данных
NVLink третьего поколения
Для связи между графическими процессорами в вычислительных системах на базе решений Nvidia используют интерфейс NVLink, и в A100 используется уже его третье поколение, которое удваивает скорость высокоскоростного соединения между GPU, что позволяет добиться более эффективного масштабирования подобных систем. В новой версии используется больше линий на GPU и NVSwitch, она обеспечивает большую пропускную способность между GPU и улучшенные функции обнаружения и восстановления ошибок.
Третье поколение NVLink имеет скорость передачи данных в 50 Гбит/с на сигнальную пару, что почти вдвое выше скорости 25,78 Гбит/с в случае V100. Каждый линк обеспечивает пропускную способность 25 ГБ/с в каждом направлении, как и у V100, но использует вдвое меньшее сигнальных пар на канал по сравнению с V100. Общее количество линков было увеличено с 6 у V100 до 12 для A100, поэтому общая пропускная способность возросла с 300 ГБ/с до 600 ГБ/с.
Также в многопроцессорных системах на основе A100 используется и новая версия NVSwitch, значительно повышающая масштабируемость, производительность и надежность при совместной работе нескольких графических процессоров. Чип новой версии NVSwitch содержит 6 млрд транзисторов и также производится по 7 нм техпроцессу на TSMC (но на другом типе — 7FF), поддерживает 36 портов с пропускной способностью в 25 ГБ/с каждый.
Поддержка решений Magnum IO и Mellanox
Новый графический процессор A100 полностью совместим и с высокоскоростными решениями интерконнекта Nvidia Magnum IO и Mellanox InfiniBand и Ethernet для обеспечения взаимодействия многоузловых систем на основе нового GPU. Вовремя Nvidia завершила сделку по приобретению Mellanox — израильского производителя телекоммуникационного оборудования, ключевого разработчика технологии InfiniBand.
Magnum IO API объединяет вычислительные системы, сети, файловые системы и хранилища, чтобы максимизировать производительность ввода-вывода для многоядерных и многоузловых систем на основе GPU. Он взаимодействует с библиотеками CUDA-X для ускорения ввода-вывода в широком диапазоне задач, включая ИИ, анализ данных и визуализацию.
Поддержка шины PCI Express 4.0 и технологии виртуализации SR-IOV
Графический процессор A100 поддерживает шину новой версии PCI Express 4.0 (PCIe Gen 4), удваивающую пропускную способность, по сравнению с PCIe 3.0/3.1 — обеспечивается скорость передачи данных в 31,5 ГБ/с против 15,75 ГБ/с для привычных для нас разъемов x16. Это особенно важно при использовании A100 в серверных системах с центральными процессорами, поддерживающими PCIe 4.0, вроде AMD Epyc второго поколения (кодовое имя «Rome»), а также при использовании быстрых сетевых интерфейсов, вроде 200 Гбит/с InfiniBand.
A100 также поддерживает технологию виртуализации устройств SR-IOV, позволяющую предоставлять виртуальным машинам прямой доступ к аппаратным возможностям, разделяя один разъем PCIe на несколько виртуальных машин или процессов. К слову о виртуализации, тут также есть кое-что новое.
Технология виртуализации Multi-Instance GPU
Хотя потребности многих вычислительных задач постоянно растут, некоторые применения GPU не столь требовательны — например, инференс сравнительно простых моделей малого размера в задачах глубокого обучения. И для эффективного управления центрами обработки данных нужно не просто расширять возможности вверх, но и уметь эффективно ускорять меньшие рабочие нагрузки, не тратя впустую ресурсы высокопроизводительных чипов. Для этого обычно применяется разделение возможностей мощного устройства на виртуальные части, и работает это не всегда эффективно, поэтому Nvidia решила внедрить кое-что новое и тут.
В прошлом поколении GPU их вычислительные возможности позволяли нескольким приложениям одновременно исполняться на отдельных ресурсах, но ресурсы памяти были распределены между всеми приложениями, и одно из них могло создавать помехи остальным, если оно имело повышенные требования к пропускной способности памяти и кэша. В Ampere технология разделения ресурсов работает несколько иначе:
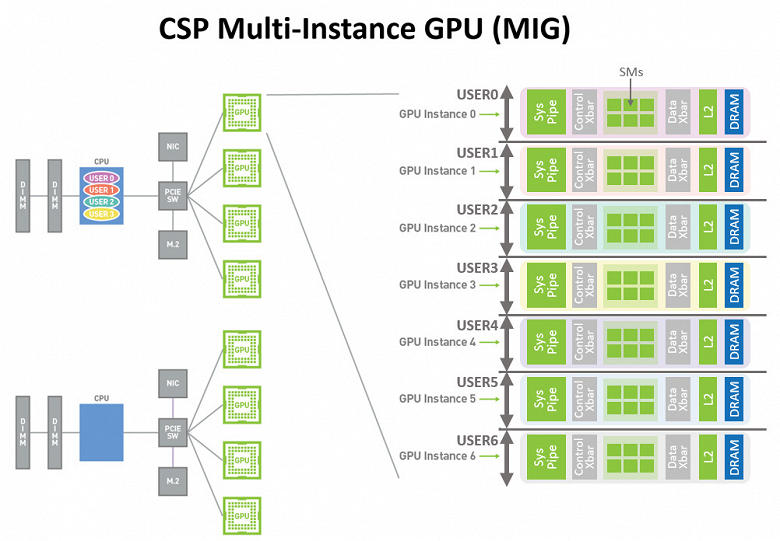
Новая возможность графического процессора A100 под названием Multi-Instance GPU (MIG) позволяет разделить графический процессор A100 на несколько разделов, называемых экземплярами графического процессора (GPU instance) — поддерживается до семи отдельных виртуальных GPU, занимающихся выполнением задач разной сложности. Каждому экземпляру обеспечивается свой набор ресурсов, включая память и кэши.
В режиме MIG, процессор A100 позволяет полнее загрузить работой его исполнительные блоки, обеспечивая параллельную работу до семи виртуальных GPU с высокой степенью надежности и безопасности. Решение обеспечивает нескольким пользователям доступ к ресурсам GPU для ускорения их приложений, оно полезно для оптимизации использования возможностей GPU, и особенно пригодится поставщикам облачных услуг — cloud service providers (CSP).
Мультипроцессоры каждого такого экземпляра GPU имеют собственные изолированные массивы данных во всей подсистеме памяти: банки кэш-памяти L2, контроллеры памяти и шины памяти назначаются для каждого экземпляра отдельно. Это гарантирует предсказуемую пропускную способность и задержки для всех пользователей, с одинаковыми объемом и пропускной способностью L2-кэша и памяти, вне зависимости от того, что делают соседние виртуальные системы.
Эта возможность эффективно разделяет доступные вычислительные ресурсы GPU для обеспечения определенного качества обслуживания (QoS) с изоляцией клиентов, что позволяет нескольким экземплярам GPU параллельно работать на одном физическом процессоре A100. Архитектура Ampere позволяет выполнять задачи на экземплярах виртуальных GPU так, как будто это физически разные устройства.
Таким образом, подключение MIG максимально увеличивает загрузку GPU при обеспечении качественного сервиса и изоляции между клиентами. Эта новая возможность особенно полезна для поставщиков облачных услуг, так как гарантирует, что ни один из клиентов не повлияет на работу других клиентов, и это касается как производительности, так и безопасности. Провайдеры облачных сервисов могут использовать MIG для повышения эффективности использования их серверов с графическими процессорами, предоставляя до 7 раз большее количество экземпляров GPU без дополнительных затрат с гарантией того, что ни один клиент (виртуальная машина, контейнер, процесс) не повлияет на работу других клиентов.
Очень важно увеличить время работы и доступности GPU при помощи обнаружения, сдерживания и исправления ошибок и сбоев, вместо принудительного сброса графического процессора. Графический процессор A100 поддерживает новую технологию, позволяющую улучшить обнаружение приложений, вызывающих ошибки, их изоляцию и локализацию. В кластерах с несколькими GPU и конфигурациях вроде MIG это особенно важно — для обеспечения изоляции и безопасности между клиентами, использующими один графический процессор.
Графические процессоры архитектуры Ampere, подключенные к NVLink, имеют более надежные функции обнаружения и восстановления ошибок — ошибки страниц на удаленном GPU отправляются обратно на исходный процессор по NVLink. Обмен сообщениями об ошибках при удаленном доступе является важной функцией устойчивости для больших вычислительных кластеров, чтобы сбои в одном процессе или виртуальной машине не приводили к сбоям в других.
Аппаратный JPEG-декодер
Из не самых ожидаемых, но любопытных новинок A100 можно отметить изменения, связанные с декодированием изображений самого популярного формата JPEG. Уже довольно давно известна ускоренная на GPU библиотека для декодирования изображений nvJPEG. Совместно с Nvidia DALI, библиотекой для загрузки и обработки изображений, она помогает ускорять задачи по классификации изображений и другие алгоритмы компьютерного зрения. Эти библиотеки ускоряют загрузку, декодирование и предварительную обработку изображений для дальнейшего использования при глубоком обучении.
Ранее уже было доступно ускорение декодирования JPEG при помощи CUDA-ядер, но в состав A100 решили включить пятиядерный аппаратный блок для декодирования JPEG, который может использовать библиотека nvJPEG для пакетной обработки соответствующих изображений. Ускорение декодирования JPEG при помощи выделенного аппаратного блока позволяет более эффективно использовать обработку на GPU, так как зачастую при глубоком обучении именно декодирование этого формата оказывалось наиболее узким местом.
Аппаратные возможности нового блока применяются на A100 автоматически при использовании функции nvjpegDecode для изображений или при помощи явного выбора аппаратного бэкэнда функцией инициализации nvjpegCreateEx. Аппаратный декодировщик ускоряет декодирование JPEG последовательного (в смысле — не прогрессивного) формата при цветовой субдискретизации YUV 420, 422 и 444.
На диаграмме показан прирост производительности декодирования JPEG-изображений YUV 420 при использовании CUDA-декодера и аппаратного декодера A100 в двух распространенных разрешениях: Full HD и 4K. Получается прирост более чем в 4 раза, а если сравнивать с полностью программным декодированием на CPU, то прирост скорости достигает 17-18 раз.
Улучшения в CUDA 11 для поддержки Ampere
Конечно же, все архитектурные улучшения Ampere были немедленно поддержаны в новой версии вычислительной платформы CUDA, объявленной одновременно с анонсом GPU. Эта платформа является наиболее популярной среди аналогичных специализированных решений. Уже тысячи приложений, использующих вычисления на GPU, используют именно решение компании Nvidia. Гибкость и программируемость их платформы, а также постоянные улучшения сделали ее предпочтительной для использования в алгоритмах глубокого обучения и других типов параллельных вычислений.
Новые функции CUDA 11 обеспечивают полную поддержку тензорных ядер третьего поколения Ampere, как и всех новых типов тензорных вычислений: Bfloat16, TF32 и FP64, умеют использовать разреженность матриц, CUDA-графы, технологию виртуализации ресурсов MIG, управление L2-кэшем и другие новые возможности нового графического процессора A100.
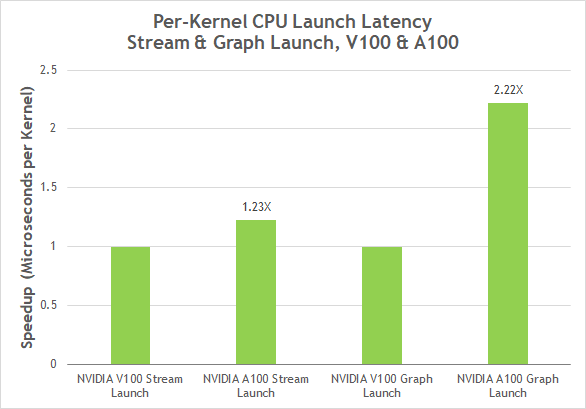
CUDA-графы, представленные в CUDA 10, представляют новую модель для запуска CUDA-вычислений. Граф состоит из нескольких операций, вроде копирования памяти и запуска связанных ядер (кернелов) на исполнение. Графы разрешают поток выполнения в формате однократного определения и многократного исполнения, и могут снизить общие накладные расходы на запуск, повысив общую производительность приложений глубокого обучения, запускающих несколько ядер, имеющих сложные зависимости. Графы CUDA теперь имеют упрощенный механизм обновлений для уже созданных экземпляров графов без необходимости их перестроения, что позволило снизить задержки при запуске ядер на исполнение на A100 до двух раз, по сравнению с V100.
В CUDA 11 к уже существующему инструментарию для разработчиков добавились новые элементы и возможности. В состав его входят плагины для Visual Studio с интеграцией Nvidia Nsight и Eclipse с Nsight Eclipse Plugins Edition. Также платформа включает автономные инструменты, вроде Nsight Compute для профилирования ядер (кернелов) и Nsight Systems — для анализа производительности всей системы. Nsight Compute и Nsight теперь поддерживаются для трех архитектур CPU: x86, POWER и ARM64.
Nvidia также анонсировала обновления программного стека компании, включая новые версии нескольких десятков библиотек CUDA-X, используемых для ускорения графики, моделирования и ИИ; CUDA 11, Nvidia Jarvis, Nvidia Merlin, фреймворка для рекомендательных систем; а также Nvidia HPC SDK, включающего компиляторы, библиотеки и инструменты, помогающие отлаживать и оптимизировать свой код для новых процессоров.
Применение A100 в вычислительных системах
Nvidia ожидает, что процессоры A100 будут использовать многие поставщики облачных услуг и сборщики систем, в том числе: Alibaba Cloud, Amazon Web Services (AWS), Atos, Baidu Cloud, Cisco, Dell Technologies, Fujitsu, Gigabyte, Google Cloud, H3C, Hewlett Packard Enterprise (HPE), Inspur, Lenovo, Microsoft Azure, Oracle, Quanta/QCT, Supermicro и Tencent Cloud.
Новые графические процессоры также будут использоваться и в суперкомпьютерах нового поколения в лабораториях и исследовательских организациях: Университет Индианы (США), Юлихский исследовательский центр (Германия), Технологический Институт Карлсруэ (Германия), Общество Макса Планка (Max Planck Computing and Data Facility, Германия), Научно-исследовательский вычислительный центр Министерства энергетики США в Национальной лаборатории Лоуренса в Беркли.
Вместе с графическим процессором A100 была анонсирована и система DGX A100 — уже третьего поколения, которая включает восемь таких GPU, связанных между собой интерфейсом NVLink. Эта система уже доступна у Nvidia и будет доступна у партнеров компании. На базе процессора A100 ожидается линейка серверов у всех ведущих производителей, включая Atos, Dell Technologies, Fujitsu, Gigabyte, H3C, HPE, Inspur, Lenovo, Quanta/QCT и Supermicro.
Чтобы ускорить разработку серверов, Nvidia создала референсный дизайн модулей HGX A100 — в форме интегрируемых плат с различными конфигурациями GPU. Соединение четырех GPU в модулях HGX A100 обеспечивает технология NVLink, а в модулях с восемью такими GPU взаимодействие между ними происходит при помощи NVSwitch. Благодаря технологии MIG, каждый модуль HGX A100 можно разбить на 56 отдельных виртуальных GPU, каждый из которых будет быстрее Nvidia T4 — отличное решение для облачных сервисов.
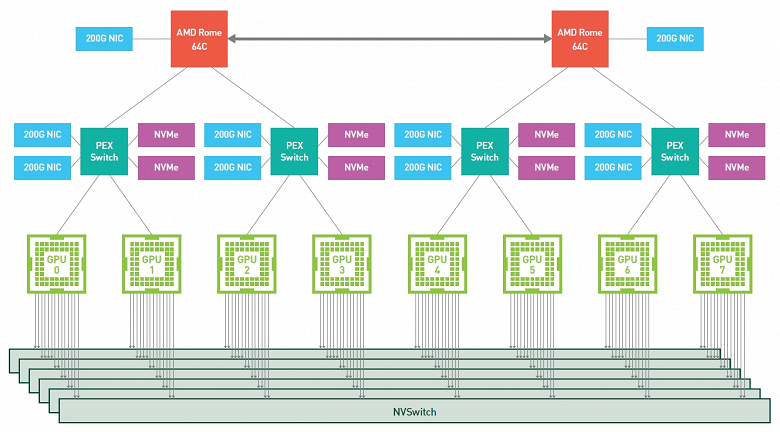
Но нас сейчас несколько больше интересует DGX A100, как готовое решение именно Nvidia. Оно предлагает производительность в задачах ИИ уровня 5 петафлопс и состоит из пары 64-ядерных центральных процессоров AMD Epyc второго поколения «Rome», имеющих 1 ТБ оперативной памяти, восьми графических процессоров A100 с тензорными ядрами, с общим объемом HBM2-памяти 320 ГБ и полосой ее пропускания в 12,4 ТБ/с. В качестве накопителей применяются твердотельные NVMe-устройства с поддержкой PCIe 4.0 и общим объемом в 15 ТБ.

Связаны GPU между собой при помощи шести интерфейсов NVSwitch с применением NVLink третьего поколения с двунаправленной полосой пропускания в 4,8 ТБ/с (чтобы наглядно показать, насколько это много, Nvidia приводит такую аналогию — этой полосы достаточно для передачи 426 часов HD-видео за одну секунду). Также применяются девять интерфейсов Mellanox ConnectX-6 VPI HDR InfiniBand 200 Гбит/с с суммарной двунаправленной полосой пропускания в 450 ГБ/с.
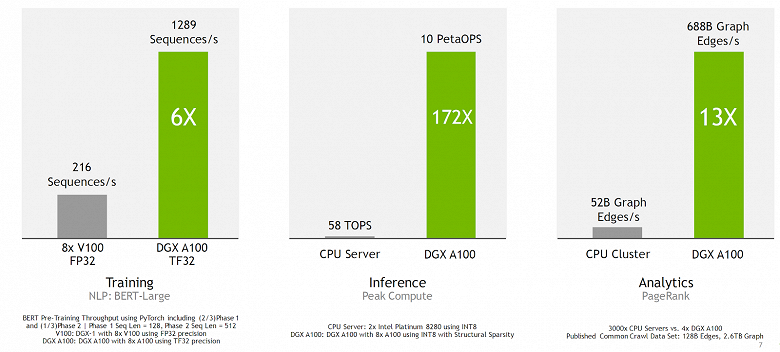
Общая производительность подобного сервера с восемью GPU на борту в ИИ задачах составляет до 10 петафлопс (с применением новой функции разреженности матриц), что значительно превышает возможности любых серверов чисто на CPU, как вы можете увидеть по следующим диаграммам, показывающим сравнительную производительность. Да и по сравнению с V100 новый графический процессор архитектуры Ampere оказался заметно быстрее — до 6 раз при обучении нейросети в задаче BERT (и в этом помог новый тип операций — TF32).
Интересно, что в Nvidia с третьим поколением DGX решили перейти на серверный процессор AMD второго поколения Epyc, а не Intel Xeon. Это было сделано по понятным причинам — как более высокой производительности за счет большего количества ядер, так и повышенной пропускной способности шины PCIe 4.0, которую решения Intel пока не поддерживают. Ведь чтобы выжать все из нескольких графических процессоров, им нужна быстрая связь между ними, и в случае с системой на Epyc все компоненты поддерживают четвертую версию PCIe: процессоры AMD, графические чипы, сетевые адаптеры Mellanox и NVMe-накопители.
Множество различных организаций по всему миру применяют системы DGX предыдущих поколений — ведущие автопроизводители, поставщики медицинских услуг, ритейлеры, финансовые институты и логистические компании. Многие из них заинтересованы в DGX A100. Поставки этих систем уже начались, крупные компании, поставщики услуг и правительственные учреждения уже разместили заказы на эти системы. Первые DGX третьего поколения отправились в Аргоннскую национальную лабораторию Министерства энергетики США, и обещано, что вычислительные возможности кластера будут направлены на борьбу с COVID-19.
Из учебных заведений первым DGX A100 получит университет Флориды, другими пользователями систем на A100 стали: Центр биомедицинского ИИ в Гамбурге, Университет Чулалонгкорна в Таиланде, Немецкий исследовательский центр ИИ, разработчик решений и услуг на базе ИИ Element AI из Монреаля, сиднейская медицинская компания Harrison.ai, компания Artificial Intelligence Office из ОАЭ, вьетнамская исследовательская лаборатория VinAI Research.
Чтобы помочь своим клиентам в создании дата-центров на базе графических процессоров A100, Nvidia также представила референсную архитектуру DGX SuperPOD нового поколения — кластера, созданного из 140 систем DGX A100, обеспечивающих производительность до 700 петафлопс в задачах ИИ. Этот кластер является одним из самых мощных суперкомпьютеров для работы с ИИ и обладает производительностью, которую могут обеспечить лишь тысячи традиционных серверов.

Объединение 140 систем DGX A100 при помощи решений свежеприобретенной Mellanox делает суперкомпьютер DGX SuperPOD особенно хорошо подходящим для обширных исследований в таких областях, как диалоговый ИИ, геномика и автономное вождение. А продуманная архитектура позволила построить столь мощную систему всего за три недели, тогда как обычно разработка компонентов с подобными возможностями требует нескольких лет.
В таком виде SuperPOD применяется в SATURNV, но ничто не мешает создать и менее производительные варианты из 20 систем DGX A100, к примеру. Системы DGX A100 уже доступны для заказа по цене от 199 000 долларов через Nvidia Partner Network. Поставщики систем хранения DDN Storage, Dell Technologies, IBM, NetApp, Pure Storage и Vast также планируют интегрировать DGX A100 в свой ассортимент.
Выводы
Nvidia уже давно нацелилась на то, чтобы их вычислительные решения прочно поселились в серверах и суперкомпьютерах по всему миру. Уже несколько лет трудно представить такие системы без GPU в решениях, предназначенных для выполнения большого количества важнейших задач человечества, вроде научных и медицинских исследований, производственных задач, исследовании больших объемов данных при использовании высокопроизводительных вычислений и искусственного интеллекта.
Nvidia является лидером в графических технологиях, поэтому компании с легкостью удается внедряться в серверы, и именно сегмент дата-центров и является самым быстро растущим для компании в целом, а другие сегменты хоть и не застаиваются, но все же не выглядят столь же мощными потенциально. Решения компании находят все более широкое применение в серверах и других высокопроизводительных системах, и совершенно неудивительно, что они вкладывают все больше и больше денег в проектирование больших чипов для высокопроизводительных вычислений и различные исследования, связанные с применением искусственного интеллекта.
Новый графический (а скорее даже вычислительный) процессор A100 обеспечивает очередной большой скачок в ускорении центров обработки данных любого масштаба, от небольшого сервера до гигантского суперкомпьютера. Мощное решение архитектуры Ampere поддерживает множество областей применения, включая HPC, исследование генома человека, 5G-сети, 3D-рендеринг, задачи глубокого обучения, анализ данных, робототехнику и многие другие.
Ускоритель вычислений A100 поддерживает платформу центров обработки данных Nvidia, включающую такие технологии как Mellanox HDR InfiniBand, NVSwitch, HGX A100 и Magnum IO SDK — эта группа технологий эффективно масштабируется от единиц до десятков тысяч GPU, предназначенных в том числе для обучения сложнейших нейросетей с максимально возможной скоростью. Развитие самых важных применений GPU требует постоянного роста производительности и возможностей вычислительных систем.
Новый графический процессор A100 по всем важнейшим параметрам превзошел своего предшественника V100, причем нужно отметить не только рост чистой вычислительной производительности, но и новые возможности по более эффективному использованию всего, что есть в этом GPU. Прирост почти по всем статьям составляет 2-3 раза, а рост объема кэш-памяти второго уровня поражает больше всего. Пожалуй, единственным по-настоящему спорным моментом в характеристиках А100 является возросший лишь в 1,3 раза объем локальной памяти — возможно, для столь мощного вычислителя стоило поставить больше HBM2-чипов. Но это частично нивелируется как раз тем самым огромным и быстрым L2-кэшем, да и возможностью сжатия данных.

Но не нужно смотреть только на цифры прироста пиковой производительности в базовых вычислениях. Да, эти показатели ближе к среднему приросту скорости реальных вычислений, но вся архитектура Ampere в основном вовсе не про это, по крайней мере в его «вычислительном» виде — A100. Даже полное название этого решения говорит о том, что основное внимание специалисты Nvidia уделили именно тензорным ядрам, которые теперь умеют вычислять гораздо быстрее и более гибко. Тензорные ядра нового GPU умеют выполнять операции новых типов, позволяя получить многократное ускорение в задачах ИИ и многих типах высокопроизводительных вычислений. Зачастую даже не требуя модификации уже существующего кода.
Конечно же, и обычные CUDA-ядра в GA100 также стали производительнее. И речь не столько о пиковых цифрах, сколько о максимально эффективном исполнении широкого ряда задач. Не зря среди приводимых Nvidia данных многие связаны именно с соотношением пиковых теоретических значений и реальной скорости вычислений. Многие улучшения в Ampere и A100 в частности направлены именно на это: серьезные изменения в работе с общей памятью и увеличенный L1-кэш, очень большой и быстрый L2-кэш, которым теперь стало можно управлять, возможности асинхронного копирования данных, сжатие данных в кэше и многое другое. По данным Nvidia, с новым A100 во многих случаях стало еще проще добиться реальной производительности, близкой к пиковой теоретической, вот лишь один из примеров:
Среди новых особенностей, предназначенных для компаний, предоставляющих облачные сервисы, можно отметить новую функцию MIG, которая позволяет разделить каждый процессор A100 на семь виртуальных ускорителей для оптимального использования ресурсов GPU, обеспечивая доступ к его возможностям для большего числа пользователей и приложений. Благодаря универсальности нового решения Nvidia, управляющие вычислительной инфраструктурой партнеры смогут удовлетворить разнообразные потребности в производительности, от несложной работы до многоузловой рабочей нагрузки.
Тут важно то, что новые технологии Nvidia позволяют подобрать требуемую вычислительную мощь для каждой задачи конкретно. Для задач попроще, типа инференса при глубоком обучении, каждый из A100 можно разделить на семь независимых инстансов GPU, а в самых сложных применениях и работе с масштабными задачами, придется делать наоборот — несколько графических процессоров объединять в один гигантский GPU при помощи интерфейса NVLink третьего поколения.
Главный вывод из всей изложенной теоретической информации состоит в том, что новая архитектура Ampere позволила графическому процессору A100 обеспечить максимальный прирост производительности в задачах ИИ среди всех предыдущих GPU компании — ускорение производительности достигает 10-20 раз по сравнению с предшественниками A100. Именно на этот тип задач Nvidia обращает внимание вот уже несколько лет, не забывая и другие применения.
Ждем и пользовательских решений компании, предназначенных для игрового сегмента. Говорят, что их появления можно ожидать к осени, и что в этот раз архитектуры вроде бы не будут отличаться (в прошлом поколении были Volta для вычислительных решений и Turing для игровых, хотя это разделение и можно считать номинальным). Будущие GeForce возьмут многое из того, что было сделано для вычислений в GA100, но наверняка в них добавятся ядра для аппаратного ускорения трассировки лучей. Также возможны интересные нововведения, связанные с улучшенными тензорными ядрами. DLSS 2.0 хорош, но ведь можно сделать еще лучше, правда?
NVIDIA RTX vs GTX: в чем разница?
Если вы не в курсе последних новостей в мире аппаратного оборудования или только недавно заинтересовались сборкой своего ПК и думаете о приобретении видеокарты от Nvidia, то, несомненно, заметили, что упомянутая компания предлагает два разных на первый взгляд типа графических процессоров: GTX и RTX.
Итак, что же это все означает, в чем разница между моделями GTX и RTX, и какую из них стоит выбрать? Мы ответим на все эти вопросы, так что рекомендуем прочитать статью до конца!
- 1 Основы
- 2 GeForce 20 / 30 против GeForce 16
- 3 Что такое RT ядра?
- 4 Что такое тензорные ядра?
- 5 Заключение
Основы

Все игровые графические процессоры Nvidia принадлежат их собственному бренду GeForce, который появился в 1999 году с выпуском GeForce 256. С тех пор компания выпустила сотни различных видеокарт, а кульминацией стали четыре последних модельных ряда: серия GeForce 20, выпущенная в 2018 году, серия GeForce 16, выпущенная в 2019 году, серия GeForce 30, выпущенная в 2020 году, и серия GeForce 40, выпущенная в 2022 году.
На сегодняшний день серии GeForce 20, GeForce 30 и GeForce 40 состоят исключительно из графических процессоров RTX, а серия GeForce 16 – из видеокарт GTX. Итак, что же означают все эти буквы? На самом деле ни GTX, ни RTX, не являются аббревиатурами и не имеют конкретного значения как такового. Они существуют просто ради маркетинговых целей.
Nvidia использовала несколько похожих двух- и трехбуквенных обозначений, чтобы предоставить пользователям общее представление о том, какую производительность может предложить каждый графический процессор. Например, производители использовали такие обозначения, как GT, GTS, GTX, а также многие другие на протяжении многих лет, однако лишь GTX и новая RTX «выжили» до наших дней.
GeForce 20 / 30 против GeForce 16

Прежде всего мы должны отметить, что серии 20 и 16, то есть последние графические процессоры RTX и GTX, основаны на одной и той же микроархитектуре видеокарты Turing, которую Nvidia впервые представила в 2018 году. В свою очередь, серия 30 основана на архитектуре Ampere, а серия 40 основана на новейшей архитектуре Ada Lovelace.
Однако, несмотря на то, что GeForce 20 и 16 основаны на одной архитектуре, 20-я вышла первой. После запуска в 2018 году, производители хотели сосредоточиться на расширенных функциях, которые могла предложить новая архитектура. Линейка состояла из графических процессоров верхней части среднего сегмента и high-end видеокарт, которые и могли продемонстрировать указанные функции, и это были первые модели под обозначением RTX.
Между тем, серия 16 появилась годом позже, потому что Nvidia нужно было предложить несколько более экономичных решений для тех, кто не мог позволить себе потратить больше 400 долларов на видеокарту. Эти графические процессоры, однако, не имели вышеупомянутых расширенных функций, поэтому сохранили старое обозначение GTX.

Тем не менее в настоящее время графические процессоры GTX действительно слабее, чем RTX, но так и было задумано самими разработчиками. Название RTX было введено в основном ради маркетинга, чтобы новые графические процессоры воспринимались как большой шаг вперед, как нечто действительно новое, а само обозначение было вдохновлено главной новой функцией, представленной в серии 20: трассировка лучей в реальном времени.
Сейчас трассировка лучей в реальном времени стала возможной благодаря RT-ядрам, которые встречаются в сериях 20, 30 и 40, и отсутствуют в моделях серии 16. Вдобавок ко всему существуют тензорные ядра, которые обеспечивают ускорение ИИ, а также повышают производительность трассировки лучей и обеспечивают суперсэмплинг глубокого обучения в играх.
Если убрать эти две ключевые характеристики из общей картины, видеокарты GTX 16 серии и графические процессоры RTX серий 20, 30 и 40 не так уж сильно отличаются. Очевидно, что более дорогие модели RTX имеют больше транзисторов, больше ядер, лучшую память и многое другое, из-за чего они способны предложить лучшую общую производительность, чем более дешевые аналоги в лице GTX. Однако они не обязательно обеспечивают лучшее соотношение цены и качества.
Итак, что это за новые функции и стоит ли покупать графический процессор RTX?
Что такое RT ядра?

Как упоминалось выше, RT ядра представляют собой ядра графического процессора, предназначенные исключительно для трассировки лучей в реальном времени.
Так что же делает трассировка лучей с графикой видеоиграх? Технология позволяет добиться более реалистичного освещения и отражений. Это достигается путем отслеживания обратной траектории распространения луча, что позволяет графическому процессору выдавать гораздо более реалистичное моделирование взаимодействия света с окружающей средой. Рейтрейсинг по-прежнему возможен даже на графических процессорах без RT ядер, но в таком случае производительность просто ужасная, даже на флагманских моделях прошлых поколений типа GTX 1080 Ti или топовых видеокартах AMD.
Говоря о производительности, трассировка лучей в реальном времени на самом деле сильно влияет на производительность даже при использовании с графическими процессорами RTX, что неизбежно приводит к вопросу — стоит ли вообще использовать данную технологию?
Видео выше показывает, как трассировка лучей выглядит в игре Portal RTX: графические улучшения, обеспечиваемые трассировкой лучей, значительны, если сравнивать с оригинальной игрой без трассировки лучей. Это важное достижение в области гейминга, которое в ближайшие годы значительно улучшит графику видеоигр, особенно, если учесть, что сейчас трассировку лучей используют в том числе консоли Xbox Series и PlayStation 5.
Что такое тензорные ядра?

Несмотря на то, что трассировка лучей является наиболее «продаваемой» функцией графических процессоров RTX серий 20, 30 и 40, архитектура Turing также представила еще одну важную новую функцию в основной линейке GeForce — расширенные возможности глубокого обучения, которые стали возможны с помощью специальных тензорных ядер.
Эти ядра были представлены в 2017 году в графических процессорах Nvidia Volta, однако игровые видеокарты не были основаны на этой архитектуре. Таким образом, тензорные ядра, присутствующие в моделях Turing, на самом деле являются тензорными ядрами второго поколения. Касаемо игр, то у глубокого обучения есть одно основное применение: суперсэмплинг глубокого обучения, сокращенно DLSS, который представляет собой совершенно новый метод сглаживания. Итак, как именно работает DLSS и лучше ли он, чем обычные методы сглаживания?
DLSS использует модели глубокого обучения для генерации деталей и масштабирования изображения до более высокого разрешения, тем самым делая его более резким и уменьшая искажения. Вышеупомянутые модели глубокого обучения создаются на суперкомпьютерах Nvidia, а затем приводятся в действие тензорными ядрами видеокарты.
Суперсэмплинг обеспечивает более четкое изображение, но при этом требует меньших затрат на оборудование, чем большинство других методов сглаживания. Более того, технология может заметно улучшить производительность при включенной трассировке лучей, что хорошо, учитывая, насколько высока производительность данной функции.
Заключение

Что ж, пришло время подвести итоги: обозначение RTX было введено Nvidia в основном ради маркетинговых целей, из-за чего графические процессоры на архитектуре Turing 20-й серии выглядели как более крупное обновление, чем они есть на самом деле.
Конечно, RTX-модели оснащены крутыми новыми элементами, которые полностью раскроют свой потенциал в обозримом будущем, а что касается чистой производительности, новейшие видеокарты на архитектуре Ampere достаточно сильно опережают старые графические процессоры GTX на базе Pascal, которые продавались по примерно той же цене.
Принимая во внимание все вышесказанное, мы бы не сказали, что графические процессоры RTX стоит покупать только ради трассировки лучей и DLSS, поскольку производительность всегда должна быть на первом месте, особенно если вы хотите получить максимальную отдачу от своих денег. С другой стороны, эти технологии будут развиваться в ближайшем будущем, и через пару лет графические чипы GTX окажутся откровенно устаревшими. Если вы собираетесь приобрести новую видеокарту, то, возможно, стоит ознакомиться с данной статьей, где мы перечислили лучшие видеокарты, доступные на рынке прямо сейчас.

Люблю игры и футбол. В чай кладу одну ложку сахара.
Считаю что трассировка лучей является не столь революционной функцией ради которой стоит обновляться на новое поколение, сколько её метод оптимизации под названием DLSS. Уже который год в сети плавают слухи что у NVIDIA в рукаве был припасён ход, позволяющий сделать реальный прогресс в плане оптимизации — но зная насколько сильно компания погрязла в маркетинге, ждать от них такого подарка «бесплатно» было бы максимально глупо, и по факту так и получилось.
Трассировка же стала тем самым триггером, который заставил их применить этот козырь, и как мы видим по тестам 2.0 версии — результаты действительно впечатляющие, а уж если и вовсе отключить Трассировку, то мы как раз и получаем тот самый долгожданный буст фпс в 2 раза, который к тому же ещё и умудряется «улучшать» картинку из натива… Просто фантастика.
У них в планах сейчас вообще стоит задача добиться включения поддержки DLSS по умолчанию на уровне настройки видеоадаптера через панель нвидии, но это ориентировочно должно быть в версии 3.0, а пока что только вчера вышло обновление под номером 2.1 которое добавляет режим «Ультра производительности» для Death Stranding — кстати есть ли по этому поводу тесты?)Чего ждать в будущем? Первое время конечно всё будет сказочно — буст фпс в 2 раза это действительно круто, и только совсем глупые люди не будут таким пользоваться, особенно на самых бюджетных версиях RTX серии в виде 2060, которые были слегка быстрее и чутка дороже тех же 1660 версий, но по факту дадут двойной разрыв в производительности с ними.
Но почему же это чисто маркетинговая технология, которая по факту может работать на всех видеокартах, но нвидиа заботливо двигает её только под новые серии? Да потому что у неё есть аналог, и точно так же как и Crytek сделали свой софтовый вариант трассировки, AMD сделали на уровне софта аналог под названием FidelityFX. Естественно она получилась хуже, но тот факт что это всё базируется чисто на программном уровне — а не с фейковым использованием каких то там специальных ядер, намекает нам на то что кое кого сильно обманывают, но если всё таки довести до ума данную функцию и включить её поддержку на программном уровне — то AMD будет иметь серьёзный ответ на прорывные технологии предлагаемые Хуангом в 3 тысячной серии.Видеокарты Founders Edition от Nvidia и AMD – стоит ли покупать

Хороши ли графические процессоры Founders Edition? Если да, то стоит ли их выбирать среди других вариантов GPU?
Сегодня я расскажу вам всё, что вам нужно знать о видеокартах Founders Edition, и к тому времени, когда я закончу, вы точно будете знать, стоит ли вам выбирать одну из них.
Что такое графический процессор Founders Edition
Прежде чем я подробно объясню, что такое видеокарта Founders Edition, важно понять, как распространяются видеокарты.
Хотя все текущие видеокарты для ПК производятся Nvidia или AMD (скоро присоединиться Intel), вы, скорее всего, будете покупать видеокарту у одного из их партнеров по оборудованию, а не у самих AMD или Nvidia.
Для видеокарт, отличных от Founders Edition, процесс выглядит примерно так:
- Nvidia производит GPU. Не полноценная видеокарта, а необходимый чип графического процессора для работы видеокарты.
- После того, как графический процессор изготовлен, он отправляется партнеру AIB (Add-In Board). Это известные бренды графических процессоров, такие как EVGA и Gigabyte.
- Как только у соответствующего партнера AIB появится чип, он может делать с ним все, что захочет, прежде чем выпустить видеокарту (в определенных пределах). Это означает добавление к нему собственного охлаждения, сборку чипов для более высокопроизводительных разогнанных версий видеокарты и так далее.

С видеокартой Founders Edition процесс выглядит следующим образом:
- Nvidia производит графические процессоры и «отбирает» некоторые высококачественные чипы. Те, которые они не оставляют себе, переходят к партнерам AIB в процессе, описанном выше.
- Как только у Nvidia появятся идеальные чипы, они смогут встроить их в свои собственные карты Founders Edition с индивидуальной настройкой охлаждения. Кроме того, эти карты Founders Edition часто будут работать на более высоких тактовых частотах, чем «эталонная» спецификация, которая отправляется партнерам AIB, но партнеры AIB все равно склонны разгонять и настраивать свои видеокарты.
- Поскольку посредника больше нет, Nvidia может свободно продавать свои видеокарты Founders Edition и получать больше прибыли, чем если бы их продал партнёр AIB.
Таким образом, видеокарта Founders Edition – это видеокарта, которую вы покупаете непосредственно у Nvidia, а не у партнера. Это похоже на покупку эталонного или «стандартного» графического процессора, и, по идее, они должны быть более дешёвыми. На самом деле, с тех пор, как Nvidia запустила линейку Founders Edition в 2016 году, видеокарты FE рассматриваются как продукты премиум-класса с наценкой от базового графического процессора.
Есть ли у AMD графические процессоры Founders Edition
Хотя у AMD есть видеокарты с эталонным дизайном, которые она продаёт напрямую потребителям, у них нет маркетинговой или ценовой надбавки по сравнению с видеокартами, не являющимися эталонными.
Именно так Nvidia поступала до выпуска GTX 10-й серии в 2016 году, но с тех пор только AMD несёт факел продажи дешёвых видеокарт с эталонным дизайном напрямую потребителям.
Это никоим образом не делает покупку эталонных графических процессоров у AMD худшим вариантом, особенно если вы выбираете видеокарту, которая превосходит аналогичный вариант Nvidia по цене.
Всегда ли видеокарты Founders Edition имеют продувное охлаждение
Распространённым в наши дни мифом является то, что все видеокарты Founders Edition выполнены в стиле воздуходувки, но это миф, который основан на некоторых фактах.
Хотя сейчас это не так, было время, когда стандартные конструкции Nvidia и AMD выпускались только продувным охлаждением, а не с открытым или какими-либо альтернативами.

Начиная с выпуска серии RTX 20, Nvidia начала использовать конструкцию открытого охлаждения с двумя вентиляторами для своих видеокарт Founders Edition вместо традиционной конструкции кулера с вентилятором.
В серии RTX 30 по-прежнему используются двойные вентиляторы, но это нечто вроде гибрида двух стилей дизайна, поскольку один вентилятор служит для выпуска воздуха из корпуса, а другой служит для проталкивания воздуха вверх через радиатор (и отвода некоторого количества тепла в корпус).
Для хорошо вентилируемого корпуса, отличного от Mini ITX, обычно предпочтительнее использовать графическую карту открытого типа.
Видеокарты с открытым охлаждением, как правило, работают немного тише, холоднее и быстрее, чем их аналоги в стиле воздуходувки, особенно с заводским разгоном, который распространён как у Nvidia, так и у других поставщиков графических процессоров.
Тем не менее, есть сценарии, когда видеокарта в стиле воздуходувки лучше, чем открытая альтернатива.
Если вы собираете корпус Mini ITX или надеетесь запустить установку с несколькими графическими процессорами (оба сценария, когда открытая видеокарта будет задыхаться и отводить больше тепла на остальные компоненты ПК), продувная система охлаждения будет работать намного круче.
Это связано с тем, что два разных стиля охлаждения видеокарты по-разному отводят тепло.
Видеокарта с открытым охлаждением избавляется от тепла, отводя его практически во всех направлениях после забора холодного воздуха от вентиляторов. Это нормально в большом корпусе с хорошим воздушным потоком, но становится проблематичным, если охлаждающим вентиляторам не хватает места для дыхания.
Кроме того, если воздушный поток слабый, вы рискуете, что ваша видеокарта сделает другие компоненты вашей системы более горячими, поскольку это тепло не рассеивается эффективно от вашей машины.
Между тем, продувная видеокарта забирает весь воздух от одного вентилятора… и выпускает его вне корпуса.
Если вы устанавливаете видеокарты в конфигурации с несколькими графическими процессорами (или в конфигурации NVLink, если вы думаете о Nvidia) или встраиваете в корпус Mini ITX, вы можете добиться лучших результатов с видеокартой в стиле воздуходувки.
Говоря конкретно о видеокартах Founders Edition, серии RTX 30 FE хорошо сбалансированы для обоих сценариев.
Чем Founders Edition лучше других видеокарт
Если Nvidia готова увеличить цену и усилить рекламу видеокарты Founders Edition, что делает их намного лучше других вариантов?
Видеокарты Founders Edition заменили на рынке более дешёвые карты эталонного дизайна и указывают на готовность Nvidia напрямую конкурировать со своими партнёрами.
Я думаю, будет справедливо сказать, что Nvidia должна быть готова поддержать:
Биннинг
Чтобы ответить на этот вопрос, давайте обсудим биннинг. Мы вскользь упоминали об этом процессе ранее в статье, но теперь пришло время объяснить его немного подробнее.
По сути, при производстве любого процессора (GPU или CPU) происходит нечто, называемое процессом биннинга.
Процесс биннинга включает в себя тестирование каждого производимого чипа и их «группировку» на основе производительности.
Интересным моментом в биннинге является то, что иногда он может привести к получению совершенно нового продукта. Например, предположим, что Intel пытается создать шестиядерный процессор Intel, но в процессе биннинга узнает, что два из этих ядер не работают достаточно хорошо, чтобы продать весь пакет.
Было бы пустой тратой хороших материалов просто выбрасывать всё это, поэтому вместо этого ЦП переименовывается в четырехъядерный, неработающие ядра отключаются, а конечный продукт продаётся потребителям.
В случае с видеокартами Founders Edition биннинг является одной из причин, по которой они считаются хорошим вариантом.
Поскольку Nvidia отвечает за производство всех своих чипов для графических процессоров, она может отбирать высокопроизводительные чипы для использования с видеокартами Founders Edition, прежде чем продавать остальные своим партнёрам.
Тем не менее, это не означает, что у каждой партнёрской видеокарты слабый чип – многие видеокарты высокого класса также тщательно отбираются.

Помимо биннинга, также стоит обсудить цены и охлаждение.
Если вам посчастливится получить видеокарту Founders Edition, когда она будет доступна в прямой продаже на веб-сайте Nvidia, вы получите карту по рекомендованной производителем розничной цене, а не по резко завышенным ценам в других торговых точках.
К сожалению, это практически не реально, и вне этого сценария карты Founders Edition могут быть дороже, чем альтернативные варианты.
Между тем, видеокарты Founders Edition текущего поколения довольно хорошо охлаждаются благодаря их гибридному подходу к дизайну кулера.

Благодаря хорошему биннингу в дополнение к хорошему охлаждению, видеокарты Founders Edition – жизнеспособный выбором для разгона, который поможет энтузиастам выжать из видеокарты немного дополнительной производительности и срока службы.
В чём видеокарты Founders Edition проигрывают?
Теперь давайте обсудим, в чём недостатки видеокарт Founders Edition.
Большой проблемой является цена, особенно если вы не покупаете напрямую у Nvidia. Ещё до нехватки чипов карты Founders Edition поставлялись с надбавкой к цене по сравнению с бюджетными вариантами от партнеров AIB.
Во время пандемии, когда большинство видеокарт продавались в магазинах или у спекулянтов по ценам намного выше, чем MSRP, эта разница стала менее очевидной… но это не то, что я бы назвал победой для карт Founders Edition.
Следующее – всё ещё сырая производительность и потенциал для разгона.
Хотя это правда, что карты Founders Edition довольно хороши в этом отношении, они не совсем соответствуют видеокартам самого высокого уровня от партнёров Nvidia. Например, я бы выбрал high-end EVGA RTX 3060 вместо Founders Edition RTX 3060 в любой день недели, и не только из-за более мощного охлаждения или немного более высокого разгона.
Видеокарты Founders Edition могут явно превосходить бюджетные партнёрские карты, но когда партнёры сами решают конкурировать со своим собственным биннингом и охлаждением… Nvidia не всегда выходит на первое место. Такова природа конкуренции «аппаратных партнёров».
Часто задаваемые вопросы о видеокартах Founders Edition
Являются ли эталонные видеокарты аналогом Founders Edition?
Нет. Хотя некоторые партнеры всё ещё выпускают эталонные видеокарты Nvidia, карты Founders Edition существенно отличаются от эталонных, которые Nvidia использовала для продажи.
Мы подробно обсуждали почему в статье выше, но если коротко, то видеокарта Founders Edition предназначена для прямой конкуренции с нестандартными разработками от партнёров, а не для предоставления более дешёвой точки входа.
Какие альтернативы есть для видеокарт Founders Edition?
Если вы не уверены в том, стоит ли приобретать карту Founders Edition, или просто хотите получить представление о том, что ещё следует учитывать, вы обратились по адресу.
Во-первых, давайте поговорим о нескольких вариантах, которые становятся доступными, когда вы получаете видеокарту Nvidia от партнёра вместо Nvidia.
Эти параметры включают в себя:
- Меньшие версии рассматриваемого графического процессора. Не у всех графических процессоров есть более компактные партнёрские версии, но для тех, у кого есть, получение видеокарты меньшего размера, которая действительно может поместиться в компактный корпус, может быть лучшим вариантом, чем более громоздкая конструкция видеокарты Founders Edition или партнёра.
- Видеокарты высокого класса с лучшим охлаждением, лучшим потенциалом для разгона или и тем, и другим. Особенно от таких брендов, как EVGA, есть множество вариантов отличных видеокарт Nvidia без необходимости покупать Founders Edition. Вы вряд ли будете охлаждать жидкостью Founders Edition, но карта EVGA может поставляться с жидкостным охлаждением!
- Полноценные видеокарты для использования в конфигурациях с несколькими графическими процессорами или сборках ПК Mini ITX. Как обсуждалось ранее в статье, охлаждение с помощью вентилятора имеет свои уникальные преимущества, и текущее поколение карт Founders Edition по-прежнему отводит часть тепла в остальную часть корпуса. Осознанная покупка видеокарты в стиле воздуходувки может быть лучшим вариантом для многих пользователей.
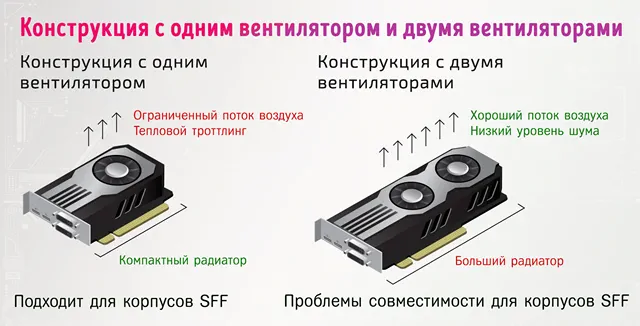
Вывод – хороши ли Founders Edition
Чтобы завязать аккуратный бант на всём этом, давайте вернёмся к первоначальному вопросу: хороши ли графические процессоры Founders Edition?
Конечно, да. Тем не менее, они не являются лучшими в большинстве ситуаций.
Проведите исследование и выберите видеокарту, которая лучше всего подходит для ваших конкретных потребностей – это может быть Founders Edition, но также может быть любая конкурирующая альтернатива от партнёров.
Источник https://www.ixbt.com/3dv/nvidia-ampere-a100-gpu-review.html
Источник https://cubiq.ru/nvidia-rtx-vs-gtx-v-chem-raznitsa/
Источник https://windows-school.ru/blog/videokarty_founders_edition/2022-06-24-970






